
MultilingProfiler is a freely available online tool for profiling the vocabulary in French, German and Spanish texts. It is developed by the University of York in partnership with Prof. Laurence Anthony (Waseda University).
MultilingProfiler helps users assess the suitability of written texts and listening transcripts for target learner groups using four list types (see below for a full description of each):
- Customisable word frequency lists
- Word lists aligning with the new GCSE
- Cumulative weekly word lists aligned with the LDP schemes of work
- Custom lists
This makes it very quick and easy to find out how many of the words in a text are included on a particular list, and to adapt texts or add glosses as necessary. Words that are ‘on list’ appear black in text profiles, and words that are ‘off list’ appear orange. Users can edit texts directly in the profiling window and immediately profile the adapted versions again.
Words and word families can be added to any word list embedded in MultilingProfiler using the ‘Add to List’ function. Statistical information about the coverage provided by the lists (both including and excluding words added by the user) is provided in the ‘Word Statistics’ and ‘Word Family Statistics’ tables directly beneath the profiling window.
More about the MultilingProfiler
Toggle the sections below to read more about the MultilingProfiler.
Customisable word frequency lists
MultilingProfiler can create profiles that show how many of the words in a text belong to the 1,000, 2,000, 3,000, 4,000 or 5,000 most frequent word families in French, German or Spanish.
Counting words and their inflected forms (lemmas and flemmas)
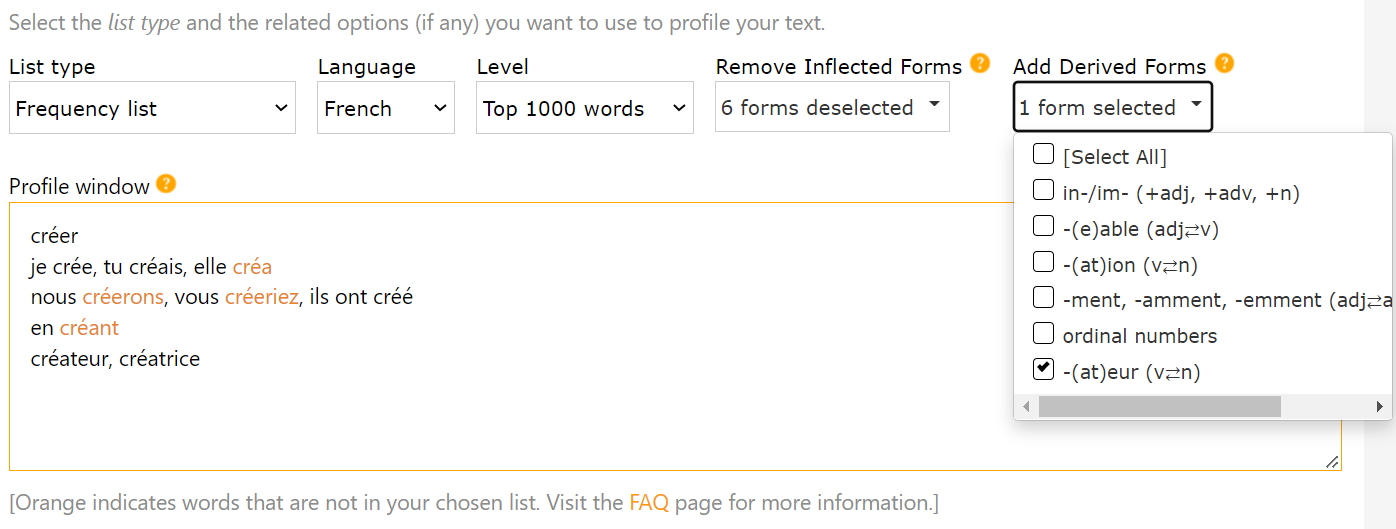
The default unit of word counting used to create frequency-based profiles is the lemma or flemma. A lemma is a set of words consisting of a base word and the inflected forms of that base word. For example, if the French créer (to create) is included in the chosen word list, all examples of créer and its inflected forms (e.g., crée, créais, créa, créerons, créé, créeriez) that occur in a text will appear in black. In some cases, base words have multiple meanings in different parts of speech, each with a different set of inflected forms. A set of words of this type is called a flemma. For example, the French son is both a possessive adjective (his) and a noun (sound). If son is included in the chosen French word list, all examples of both son (his) and its inflected forms (sa, ses) and son (sound) and its inflected form (sons) will appear in black.
Users can modify the size of lemmas and flemmas using the ‘Remove Inflected Forms’ dropdown list. This allows any grammatical patterns that learners are unlikely to recognise to be excluded from the profile. Inflected word forms that are part of deselected patterns will appear in orange.

Counting words and their inflected forms (lemmas and flemmas)
Users can also choose to create profiles by counting word families. A word family is a set of words consisting of a base word, derived forms of that base word, and the inflected forms of each. For example, if the French créer (to create) is included on the chosen French word list, users can choose to include creation (creation) and créateur (creator) in the profile as well by selecting the corresponding patterns in the ‘Add Derived Forms’ dropdown list. The derivational patterns included in MultilingProfiler’s frequency-based word lists align with those specified in the new GCSE subject content.
Users can modify the size of word families used so that only derivational patterns that learners are likely to recognise to be included in the profile. Currently, the option to profile by word family is only available for the 1,000 and 2,000 most frequent words.
The full set of word forms that belong to each lemma or flemma and word family in the 5,000 most frequent words in French, German and Spanish can be found in the ‘Word Families’ tab.

Lists compatible with the new GCSE
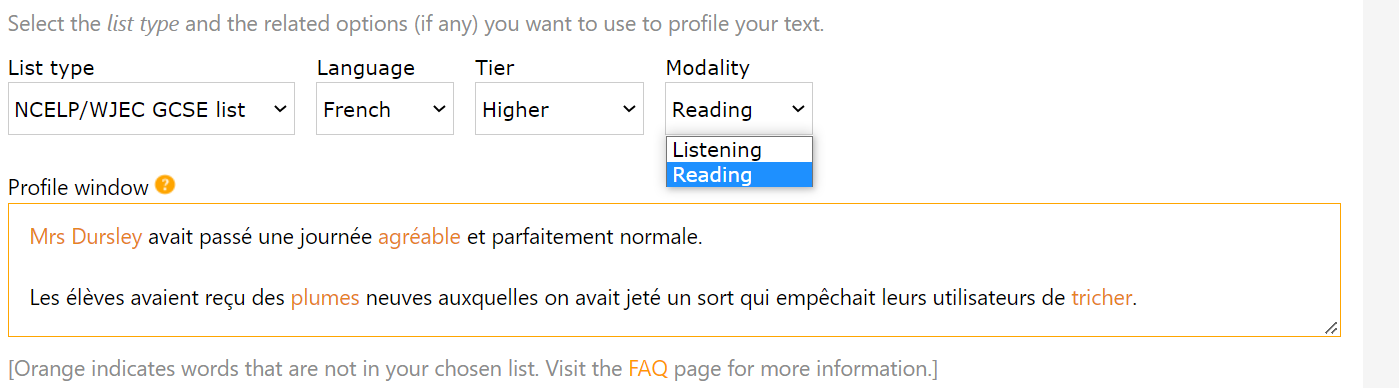
This option allows users to check a text for its compatibility with the vocabulary lists set out by awarding organisations in their new GCSE specifications (for teaching from 2024 and testing in 2026). Users can toggle between listening and reading versions of the vocabulary lists specified for Foundation and Higher levels.
The listening version includes inflected forms (lemmas) of words on the list, constrained in line with the inflectional morphology specified in the GCSE subject content. For example, plural forms of verbs in the imperfect tense are not included in the grammar content specified for Foundation French, but do appear at Higher level. Thus, verbs in the imperfect plural forms appear in orange when the Foundation list is selected, and black when the Higher list is chosen.
The reading version includes inflected and regularly derived forms (word families) of words on the list, constrained in line with the inflectional and derivational morphology specified in the GCSE subject content. For example, the derivational suffix -(at)eur is not included in the derivational morphology specified for Foundation French, but does appear at Higher level. Thus, derived forms taking the -(at)eur suffix appear in orange when the Foundation list is selected, and black when the Higher list is chosen.
Currently, only the draft LDP/WJEC GCSE word lists are embedded in MultilingProfiler (see the draft French specification) and these are subject to minor changes. However, a word list for any Awarding Organisation and level could be added in future.
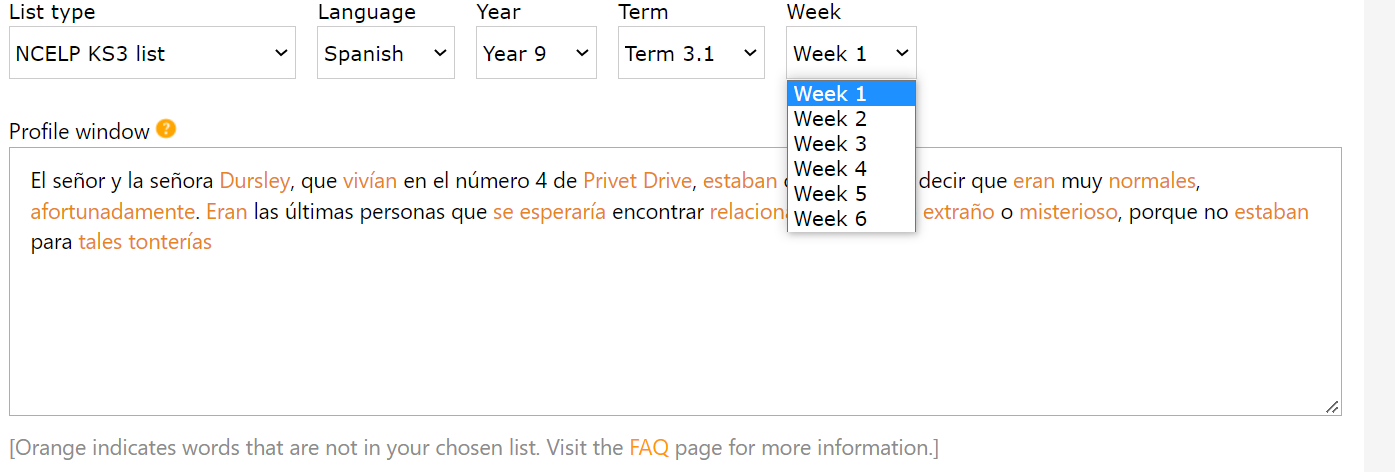
Cumulative weekly word lists aligned with the LDP schemes of work
MultilingProfiler also creates text profiles using bespoke word lists aligned with the LDP schemes of work. Teachers following the schemes of work can use this function see which words and word forms in a text have been taught at any given point in the school year. From Year 10 on, word lists differentiated for Foundation and Higher level are provided.
Custom lists
The ‘Custom list’ feature allows users to create text profiles in any of the three languages using any word list they wish. Note that the option to remove inflected forms is only available if the custom list is tagged by part of speech.
